Cuando hablamos de versiones de software estamos muy acosumbrados a decir “Esto está a partir de la versión 1.3” o “solo es compatible con la versión 2.7 en adelante” o “estoy usando la versión 1.9.0 pero ya está disponible la 1.9.2”, pero ¿qué sigifican estos números y que información nos aportan? Yo te lo cuento.
Para entender lo que representan estos números separados por puntos hay que entender primero que existen tres grandes categoarias de cambios en un software:
- Los correctivos, también conocidos como bug_fix, que son actualizaciones en las que se corrigen problemas detectados en el programa.
- Los evolutivos menores, a los que se suele llamar minor, generalmente añaden o mejoran funcionalidades pero son compatibles con versiones anteriores.
- Los cambios major, que suelen suponer cambios de gran calado que pueden suponer perder la compatibilidad con lo que teniamos hasta este momento. Por ejemplo, un campo major podría cambiar el nombre de una tabla en BBDD o la forma en la que se guardan los datos, haciendo que la versión antigua ya no “entienda” lo que hace la nueva o directamente no se pueda ejecutar.
Tres tipos de cambios, tres grupos de números separados por puntos… ¿casualidad? ¡No lo creo! justamente eso es lo que representan esos números. Y funciona de la siguiente manera:
El número más a la izquierda marca la versión major, o visto de otra forma, de alguna manera es un contador de la veces que hemos hecho cambios de calado que no podemos asegurar que sean compatibles con lo que teniamos hasta este momento.
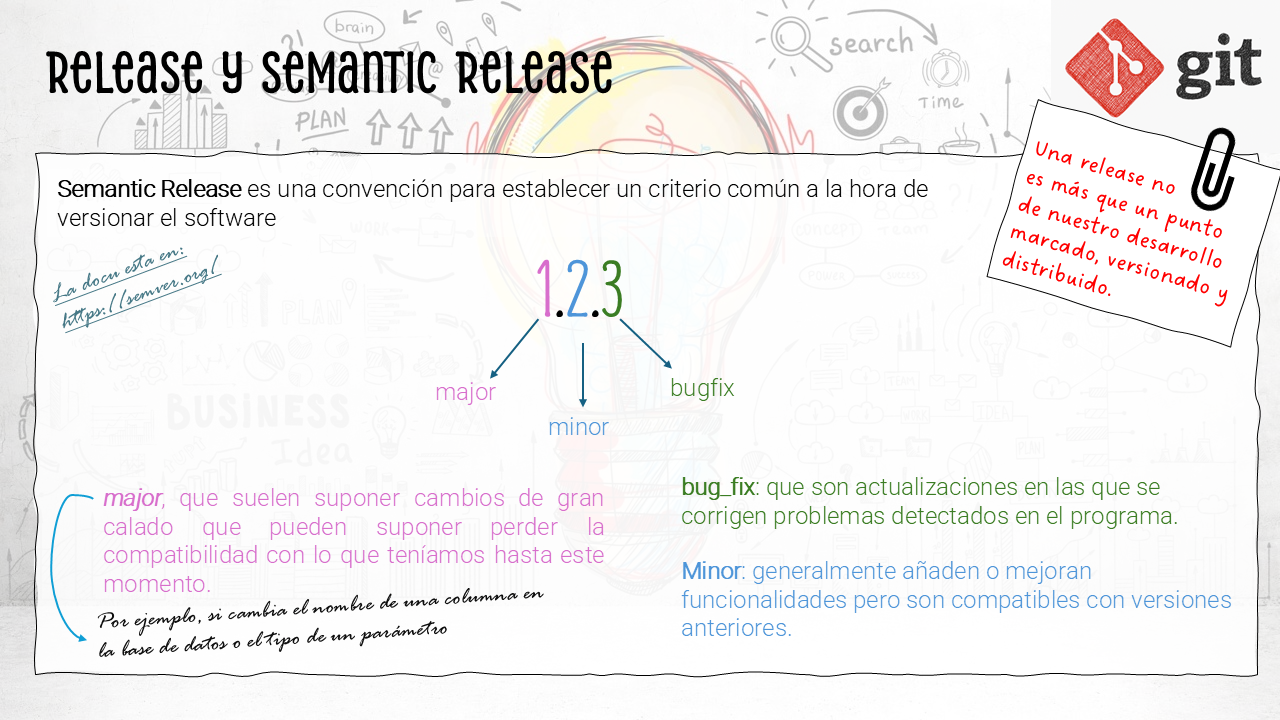
El siguiente número despúes del punto es la versión minor, una forma de tener controlado y poder relacionar una versión con las funcionalidades que incluye o no. Si por ejemplo incluimos la funcionalidad X en la versión de nuestro código que marcamos como 1.2.0 podemos sabremos que cualquier versión que tenga menos de un 2 en la posición central, no tendrá esa funcionalidad.
Y por el último, el número de la derecha del todo indica el número de corrección. De nuevo, si la versión 1.2.0 tiene un error y lo arreglamos, deberíamos marcarlo como 1.2.1, de esa forma sabemos que a parir de ese punto ese error ya no existe, pero por debajo de eso nos lo vamos a encontrar. Esto también aplica a las vulnerabilidades, por eso es tan común escuchar “esta vulnerabilidad se dá para todas las versiones anteriores a la 1.5.2, por lo que se recomienda no usar versiones anteriores a esta. Eso se debe a que en la 1.5.2 incluyen el código que arreglaba esa vulnerabilidad, pero esta sigue presente en el código anterior a este punto.
Como incrementar las versiones
Siendo un poco ordenados es sencillo mantener nuestro código con trazabilidad gracias al número de versión. Lo primero es tener claras las normas:
-
Siempre que corrijas un bug, o una serie de ellos, aumenta el ulitimo número de tu versión. Si estas trabanado sobre la versión X.Y.Z, cuando termines deberás marcarla como la X.Y.Z + 1. No es necesario incrementear el contador con cada corrección, solamente cuando vayas a crear publicar esos cambios, para que tu y tus usuarios sepan a partir de que momento esas cosas están arregladas.
-
Si añades una funcionalidad nueva, aumenta la versión minor y reinicia el contador de correcciones. Como nunca deberíamos añadir nuevas funcionalidades sin haber reparado primero lo que esta mal de las anteriores, se considera que una subida de versión minor que mejore o aumente las funcionalidades incluye cuanlquier corrección de errores que pueda haber, por lo que cuando se sube la minor, se reinicia la fix. Si vas a subir una nueva funcionalidad para X.Y.Z, la nueva tendrás que marcarla como X.Y+1.0. Visto con un ejemplo, si acabas de subir una funcionalidad nueva a la versión 1.2.5, tendrás que marcarla como 1.3.0.
-
Si haces cambios grandes, que pueden no ser compatibles con lo anterior, aumenta la versión Major y reinicia las anteriores. De nuevo se trata de que lo grande incluya lo pequeño, por eso si hacemos cambios de gran calado en la versión 1.6.99 de nuestra aplicación, la subiremos como 2.0.0.
Cosas importantes a tener en cuenta
 Esto solamente se trata de una convención, que ni mucho menos es adoptada por todo el mundo, ni es obligatoria. Algunas empresas que tienen un gran continunidad en el desarrollo de su software optan por otras vias, por ejemplo, el conocido software de domotica Home Assistan publica nuevas versiones todos los meses, por lo que decidiron usar un sistema de versionado basado en el mes y el año en el que se liberó la versión.
Esto solamente se trata de una convención, que ni mucho menos es adoptada por todo el mundo, ni es obligatoria. Algunas empresas que tienen un gran continunidad en el desarrollo de su software optan por otras vias, por ejemplo, el conocido software de domotica Home Assistan publica nuevas versiones todos los meses, por lo que decidiron usar un sistema de versionado basado en el mes y el año en el que se liberó la versión.
Las versiones deberían depender de los cambios en el software, no del tiempo. No tiene sentido hacer una versión nueva del mismo código. Si tu aplicación es estable, no tiene vulnerabilidades ni fallos conocidos y no se van a incluir nuevas funcionalidades, puede estar años con el mismo número de versión sin ningún problema.
Nada de esto es obligatorio. Puedes publicar novedades y corrección en tu software sin marcar su versión, pero hará mucho más complicado llevar una trazabilidad del desarrollo.
¿Dónde implemento esto?
Existen dos puntos clave dónde marcar la versión de tu código. Y lo ideal es que ambas estén sincronizadas.
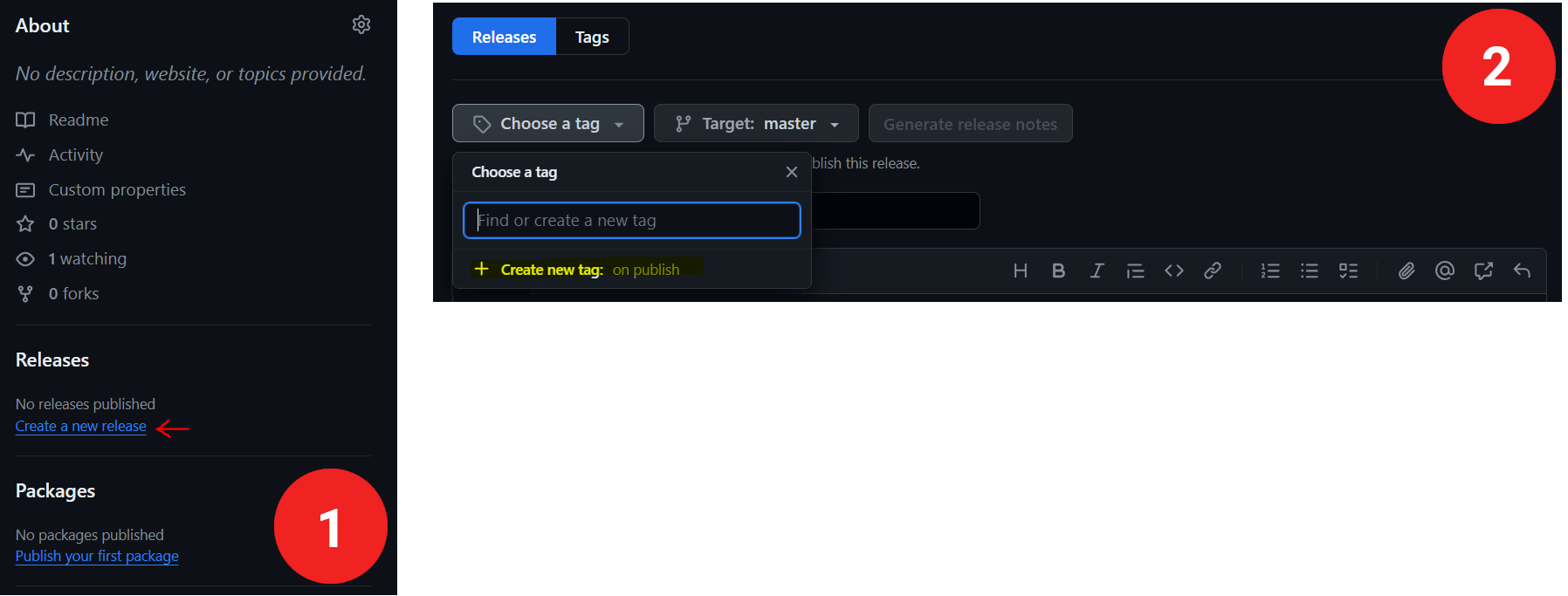
- En tu repositorio del control de versiones. En Github puedes hacerlo de las barra derecha de tu repositorio, seleccionando la opción create a new release y a continuación en el desplegable choose a tag creando una nueva tag
- En el fichero dónde se incluya la información sobre tu programa. Dependendiendo del lenguaje que uses, puede ser el package.json, el pyproject.toml … etc. Desde este fichero además puedes leer la versión para exponerla en tu front o devolverla en algún endpoint para que el usuario pueda ver forma sencilla qué versión está usando.
En el fichero package.json podemos añadir esta línea:
"version": "0.1.0",
justo debajo de la etiqueta “name”.
Relacionar la versión con lo que contiene
Ahora que tenemos marcado el código para tener trazabilidad sobre él. Necesitamos una forma de relacionar un número de versión con lo que incluye. Un documento en el que consultar si la versión 1.2.8 arregla tal problema o contiene tal feature. Esto se puede hacer en la documentación, pero lo más cómun es usar un fichero llamado CHANGELOG.md. Que como su nombre indica, es un registro de los cambios que se han ido produciendo en la aplicación.
El CHANGELOG
Puedes hacerlo en el formato y forma que quieras, pero lo más común es que sea un documento de markdown incluido en el propio repositorio, de igual forma que tenemos el README.md. Este documento puede ser todo lo detallado que quieras, pero a grandes rasgos lo importante es que incluya:
- El número de versión
- Funcionalidades añadidas (si las hay)
- Funcionalidades eliminadas (si las hay)
- Problemas de retrocompatibilidad (Si los hay)
- Problemas, errores o vulnerabilidades resuletas (Si las hay)
A partir de ahí, puedes detallar todo lo que quieras. Pero esta sería información minima necesaria para poder mantener un control de lo que supone esa nueva versión. Aquí te dejo el enlace a una plantilla de un CHANGELOG para que veas un ejemplo.
La importancia de los mensajes en los commits
Lo más fácil para poder trazar todos los cambios que se realizan en el código es ir haciendo commits cada vez que terminas con un cambio o una tarea que tuvieras pendiente. Y si a cada commit le añades una buena descripción será más sencillo saber que contiene, y volver a un punto anterior en caso de que sea necesario. Pero además, como valor añadido, hacerlo de esta manera te permitirá tener una lista de todo lo que has hecho siemplemente listando los mensajes de los commits.
Para marcar que tipo de cambio implica el commit, te recomendamos que uses el formato establecido para la semantic release. Que es el siguiente:
tipo : comentario
Supongamos que hemos detectado que algunas ocasiones el valor de una variable es 0, y en una parte de nuestro código dividimos un valor entre esa variable, lo que supone un error que crashea nuestra aplicación. Lo solucionamos y vamos a hacer el commit. Como el cambio es para arreglar un bug, el tipo será “fix” (si añadiramos una funcionalidad, sería “feat”). Así que el commit debería ser algo similar a esto:
git commit -m "fix : impedir la división entre cero"
Y todo esto hay que hacerlo a mano
 Rotundamente NO esto es un trabajo repetitivo y procedimentado que no suele resultar muy atractivo para ningún desarrollador. Lo bueno de los trabajos repetitivos y procedimentados es que se pueden automatizar. Y ya sabes… si vas a hacer algo más de dos veces, automatizalo.
Rotundamente NO esto es un trabajo repetitivo y procedimentado que no suele resultar muy atractivo para ningún desarrollador. Lo bueno de los trabajos repetitivos y procedimentados es que se pueden automatizar. Y ya sabes… si vas a hacer algo más de dos veces, automatizalo.
Lo que yo te recomiendo es que utilices las github actions o los pipelines de gitlab para hacer esto. Existen actions ya creadas que puedes añadir fácilemente y que pueden realizar todo lo que hemos visto (incluido el CHANGELOG) de forma automatica cuando tu decidas. Yo te recomendaría que lo hicieras cuando hagas el merge de una rama a tu rama main, es un buen momento para ejecutar todo el proceso que de como resultado:
- Una tag con el nuevo número de versión.
- Una release con lo que incluye esa tag.
- El Changelog actualizado.
IMPORTANTE: Esto no va a funcionar si no creas los commits con el formato indicado anteriormente.